Character Encoding(字符编码)- 1
2020-11-22
0. 前言
上一篇讲完 Base64 Encoding 之后,我对编码产生了浓厚的兴趣,所以这篇继续来聊聊编码。
1. Morse Code(摩尔斯电码)
最早的电信编码是Morse Code (摩尔斯电码 - 发明于 1836 年),国际通用的 Morse Code 有以下 5 个元素(可以想象成 5 进制):
- 点:1
- 线(划):111
- 点和线(划)之间的时间间隔为 1 单位:0
- 字母之间的时间间隔为 3 单位:000
- 单词之间的时间间隔为 7 单位:0000000
Morse Code 可以把英文字母、数字、标点符号用以上 5 个元素编码之后进行传输。Morse Code 属于字符编码的鼻祖,它的传输方式可以是灯光、无线电、声波等。
Morse Code 经常出现在影视作品里面,比如电影《寄生虫》,找到一篇相关文章,挺有意思的(如何用摩尔斯电码发韩语 )。
中文电码 比较复杂,1873 年的时候有个法国人挑了 6800 多个常用汉字,编成了第一部汉字电码本《电报新书》。
中文电码表一开始是从 0000-9999 表示 1 万个汉字,后来发现不够用,又增加了一倍。
2. Character Encoding(字符编码)
在计算机领域,Character Encoding (字符编码)的目的是则把字符变成二进制的 01 进行传输。
字符编码常用术语
- character(字符):有语义的最小单位字符;
- character set(字符集):多个字符组成的集合,可能被多种语言使用,比如 Latin character set(拉丁字符集)被用于英文和大部分的欧洲语言;
- coded character set(简称 CCS,编码字符集):每个字符编码后成为一个独特的数字;
- code unit(码元):把每个字符通过一个特定的编码形式转化成 bit 流,有些地方也称之为 code value(码值);
- code space(编码空间):编码的整数区间(比如 8-bit 就是 00000000-11111111)
- code point(码位):字符集或编码空间中的任意一个值(比如 00000000 就是一个码位);
PS:翻译有可能不准,可以参考原文。
- A character is a minimal unit of text that has semantic value.
- A character set is a collection of characters that might be used by multiple languages. Example: The Latin character set is used by English and most European languages, though the Greek character set is used only by the Greek language.
- A coded character set is a character set in which each character corresponds to a unique number.
- A code point of a coded character set is any allowed value in the character set or code space.
- A code space is a range of integers whose values are code points
- A code unit is a bit sequence used to encode each character of a repertoire within a given encoding form. This is referred to as a code value in some documents.
HTTP 和 MIME 语境
- character set = character encoding(字符集=字符编码)
- character set ≠ coded character set(字符集 ≠ 编码后的字符集)
A “character set” in HTTP (and MIME ) parlance is the same as a character encoding (but not the same as CCS).
常见码元(Code Unit)
接下来我们先看看 7-bit 的 US-ASCII。
3. US-ASCII(美国信息交换标准代码)
ASCII (American Standard Code for Information Interchange), is a character encoding standard for electronic communication. ASCII codes represent text in computers, telecommunications equipment, and other devices. Most modern character-encoding schemes are based on ASCII, although they support many additional characters.
ASCII 简介
- 出生于 1960 年代,中文名【美国标准信息交换码】;
- 一种早期的编码格式,把符号变成 01;
- 支持 7-bit 编码(128 个字符);
- 缺陷:只支持英文和基本的符号(比如空格,换行),不支持其他语言和符号(128 个编码不够用了= =);
128 还是 127?
在某些文章里面看到这样的表述:【ASCII 对应的是 127 个字符】,我思考了一下,这个计算方式应该是人为忽略了 0 。在 ASCII 表格里面,0 代表虚无(NULL)的意思,有些人可能因此把它排除掉了。
我认为还是说 128 比较严谨,毕竟是 2 的 7 次方。
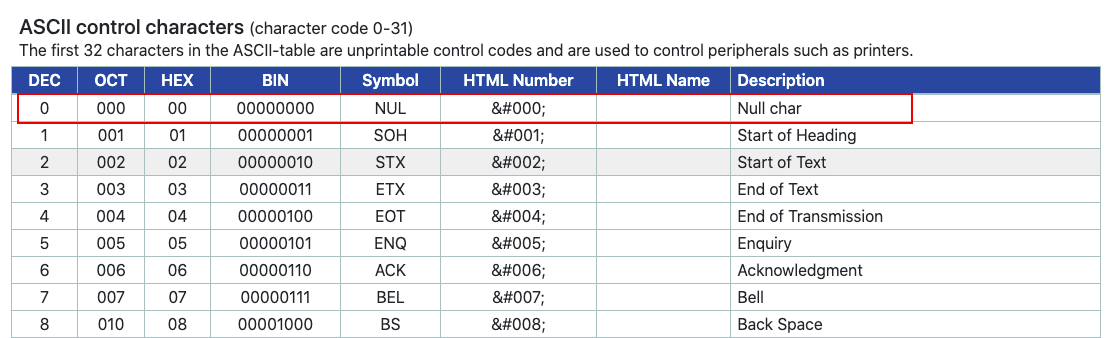
7-bit 还是 8-bit?
还有一些文章会说 ASCII 是 8-bit 编码,这也是不准确的表述。8-bit 的 ASCII 是我们接下来要讲的 EASCII。虽然 EASCII 是 ASCII 的变体,但不能简单地把 ASCII 等同于 8-bit 编码。
4. Extended ASCII(EASCII)
1970 年代,计算机行业开始普遍接受 1 Byte = 8 bit 的设定,在这个背景下,ASCII 也要升级成 8-bit,于是大家就搞起了 Extended ASCII.
冷知识:Octet (八字节)是一种更精确地表示 Byte 的说法。
When computers and peripherals standardized on eight-bit bytes in the 1970s, it became obvious that computers and software could handle text that uses 256-character sets at almost no additional cost in programming, and no additional cost for storage. (Assuming that the unused 8th bit of each byte was not reused in some way, such as error checking, Boolean fields, or packing 8 characters into 7 bytes.) This would allow ASCII to be used unchanged and provide 128 more characters.
Eventually, as 8-, 16- and 32-bit (and later 64-bit) computers began to replace 12-, 18- and 36-bit computers as the norm, it became common to use an 8-bit byte to store each character in memory, providing an opportunity for extended, 8-bit relatives of ASCII. In most cases these developed as true extensions of ASCII, leaving the original character-mapping intact, but adding additional character definitions after the first 128 (i.e., 7-bit) characters.
EASCII 简介
-
出生于 1970 年代,中文名【延伸美国标准信息交换码】;
-
扩展方式:从 7-bit 升级成了 8-bit
ASCII 定义的那些字符,统一在最前面增加一个 0;
EASCII 的扩展字符有 128 个(129-256);
EASCII 的规则是,增加的 128 个扩展字符只能被用于文字,不能被用于标签、关键词或者其他对于解释器来说有特殊意义的地方;
-
增加哪 128 个字符呢?
这个就有意思了,不同的计算机厂商、不同的国家地区都有自己的版本;
比较常见的一种是ISO/IEC 8859-1 ,又称 Latin-1 或西欧语言;
还有一种常用的编码表是 Windows-1252 ,但这个编码表从来没有成为正式的 ANSI 标准;
Windows-1252 编码表链接:https://www.ascii-code.com/
Although these encodings (ISCII, VISCII) are sometimes referred to as ASCII, true ASCII is defined strictly only by the ANSI standard.
There are many extended ASCII encodings (more than 220 DOS and Windows codepages).
In the range 128 to 159 (hex 80 to 9F), ISO/IEC 8859-1 has invisible control characters, while Windows-1252 has writable characters.
例 1
| 编码方式 | 符号 | 结果(2 进制) | 结果(10 进制) |
|---|---|---|---|
| ASCII | A | 1000001 | 65 |
| EASCII | A | 01000001 | 65 |
例 2 - 基于 Latin-1
| 编码方式 | 符号 | 结果(2 进制) | 结果(10 进制) |
|---|---|---|---|
| ASCII | ¥ | 查无此人 | 查无此人 |
| EASCII | ¥ | 10100101 | 165 |
ESACII 是一个标准编码方式吗?
首先,EASCII 只是 ASCII 的扩展版,这个扩展版有很多不同的版本;
所以,EASCII 不是一个唯一的固定的编码标准,它只是对于基于 ASCII 扩展之后的 8-bit 编码的一个统称。
你有没有注意到,我们说常见码元的时候,里面并没有 EASCII?
另外,人们提到 EASCII,往往说的是其中的一个版本(比如 ISO/IEC 8859,UTF-8),没有人会直接说 EASCII,因为实在是太多种了。
Multi-byte character encodings(多字节字符编码)
由于 8-bit 只能代表 256 个不同的字符,超过 256 个怎么办呢?那我们就用多个 8-bit 来表示多出来的字符吧~
这样的编码方式就被称作 Multi-byte character encodings,它是 variable-width encoding(可变长度编码)的一种最常见形式。
假如编码的时候所有属于 ASCII 的字符都用一样的码位,而且这些码位只用于 ASCII 表格里面所定义的字符,那么这种多字节字符编码方式就被称作"真正的 EASCII",比如 UTF-8 就是其中之一。
EASCII 的意义
对于一些编程语言和文档语言来说,满足 EASCII 的定义是非常重要的。一方面,EASCII 相比于 ASCII 新增了 128 个字符,满足了很多人类语言符号的需求;另一方面,计算机的解释器可以继续基于 ASCII 标准来解释关键的内容(只要确保新增的字符不用于关键内容)。
还有些人错误地把没有满足 EASCII 定义的那些 8-bit 编码方式统统称为 ASCII 扩展版,这样的表述是不严谨的哦~
5. 结语
本文主要讲了:
- 字符编码的鼻祖(摩尔斯电码)有 5 个元素;
- 字符编码的常见术语:码元,码位…;
- US-ASCII 编码是 7-bit;
- EASCII 不是一个统一的编码标准,只是 ASCII 编码的 8-bit 扩展版;
- 多字节字符编码是可变长度编码的一种最常见形式,满足 EASCII 定义的多字节字符编码也是真正的 EASCII;
最后来个思考题:为什么我们需要 Base64 编码?