Unicode - 5 层字符编码模型
2020-11-25
0. 前言
上一篇 讲 EASCII 的时候提到了一个常见标准:ISO/IEC 8859-1 ,虽然这个标准非常流行,但是在使用不同语言的国家之间经常发生不兼容的情况。
比如:电脑从英文切换到中文的时候,ISO 8859-1 可能就会出现问题,毕竟它只多了 128 个字符,中文的方块字哪够用啊~
于是,人们对【统一码】有了强烈的需求。假如有一种编码方式,能够涵盖世界上所有的字符,那就完美了!
下面,我们先来聊聊 Unicode 的 5 层编码模型。
1. Unicode(统一码)简介
- 出生于 1987 年,是 IT 行业的统一编码标准,也是一个字符集(Univeral Coded Character Set - UCS);
- 这个标准由 Unicode Consortium (Unicode 联盟)维护,这个联盟的宗旨是让 Unicode 取代其他的编码,成为唯一标准;
- 截止 2020 年 3 月,有 14 万多个字符;
- Unicode 可以用不同的编码方式来实现,比如 UTF-8, UTF-16, GB18030 (中国版),这些编码方式必须要能够编码所有的 Unicode 字符,才算得上是一个合格的编码方式哦~

2. Unicode 编码模型解析
我参考的是 Unicode 官网第 17 号技术报告 ,值得注意的是,这只是一份技术报告,为最终的实现提供指导,虽然 Unicode 使用了这个模型,但并不代表模型的全部要求都已经被实现。
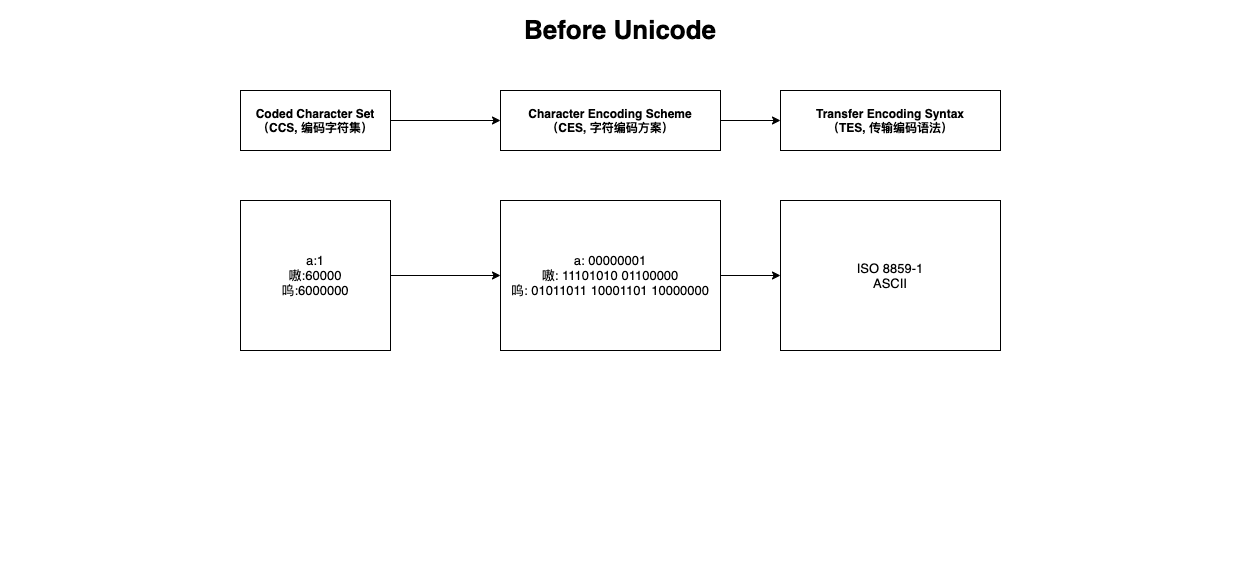
缘起 - 3 层模型
5 层模型是根据 IAB 模型所定义的三层模型而扩展的,IAB 定义了:
- Coded Character Set - CCS
- Character Encoding Scheme - CES
- Transfer Encoding Syntax - TES
Internet Architecture Board (互联网架构委员会)
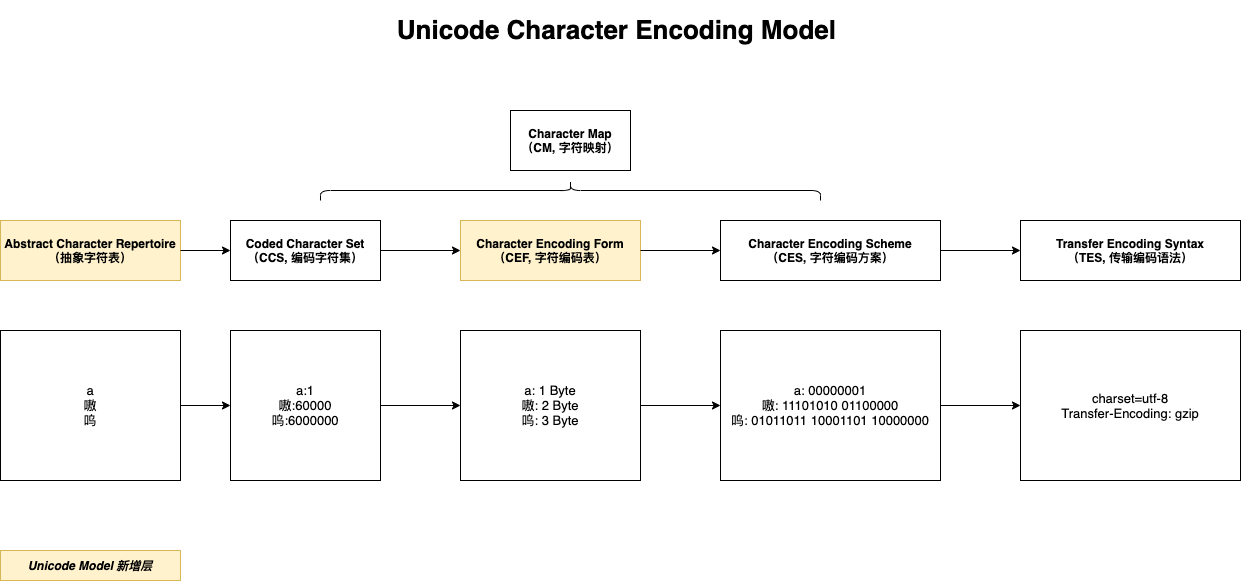
5 层字符编码模型
基于 3 层模型,Unicode 采用的 Character Encoding Model 增加了 ACR 层和 CEF 层,下面我们逐一解析。
1. Abstract Character Repertoire(简称 ACR,抽象字符表)
字符表定义了所有的字符,字符表可以是封闭的也可以是开放的;
- 封闭的就是定死了所有的字符,不能再加新的(比如 ASCII);
- 开放的就是可以加新的进去(比如 Unicode);
the set of characters to be encoded, e.g., some alphabet or symbol set
2. Coded Character Set(简称 CCS,编码字符集)
这是一个 function,用来把字符映射成 code point(码位);
- 可以理解成一个 dictionary,输入字符,输出码位;
- 比如大写 A 就对应码位 65;
a mapping from an abstract character repertoire to a set of non-negative integers
3. Character Encoding Form(简称 CEF,字符编码表)
用来把码位映射成码元(code units),如 2 Byte,4 Byte;
- 假如系统是 16 位(2 Byte)的,我们只能映射 2^16 种不同的字符,那么超出这个范围的码位就必须用多个 16 位(比如 4 Byte)来表示;
a mapping from a set of non-negative integers (from a CCS) to a set of sequences of particular code units of some specified width, such as bytes
4. Character Encoding Scheme(简称 CES,字符编码方案)
用来把 CEF 输出的码元变成最终的 Byte,然后就可以传输了,这个步骤决定字符的储存方式。
- UTF-8, UTF-16, UTF-32… 这些都是 CES;
- 大部分的系统都用 UTF-8 或者 UTF-16BE 作为 Unicode 的编码格式;
- CES 还分为 simple CES, compound CES, compressing CES。
a mapping from a set of sequences of codes units (from one or more CEFs) to a serialized sequence of bytes
5. Transfer Encoding Syntax / Higher Level Protocol(简称 TES,传输编码语法/高层机制)
比如指明编码标准(utf-8 还是 utf-16),当单一符号在不同地区有变体的情况下,也可以用 XML 的语言标签(xml:lang) 或 HTML 的语言标签(lang=“en-US”)来为 unicode 提供一些额外的信息。
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charset="utf-8" />
</head>
<body></body>
</html>
a reversible transform of encoded data. This data may or may not contain textual data
注:有时候你会看到 Character Map(简称 CM,字符映射)这个术语,它可以被看做 CCS,CEF,CES 这三个层级的统称,也就是从字符直接转为 Byte 的过程。
小白版
Unicode (统一码 )和其他的编码标准最大的不同在于,它并没有直接把字符和 Byte 进行一一对应,而是分成了 4 个步骤,分别定义了:
- 哪些字符是可用的 - ACR;
- 字符对应的码位(code points)- CCS;
- 码位如何被编为固定长度的码元(code units)- CEF;
- 固定长度的码元如何被编为 Byte (01) - CES;
2-4 可以统称为 CM。
3. 图示版
图中的 CCS 码位 是我随便编的,仅做概念示例。
我对 Unicode 的理解
在计算机科学以及程序设计里面,Abstract(抽象)和分层都是非常重要的设计理念。我们从上面两张图的对比里面可以看到,仅仅是多了两个层(ACR, CEF),我们就可以避免 ASCII 和 EASCII 中出现的问题(字符太多,无法用 7-bit 或 8-bit 全部进行编码)。
可变字节长度也是一个非常重要的概念,如果所有的字符都采用同样的字节长度(4 Byte),那么我们在传输那些只需要 1 Byte 的字符时就会浪费 3 Byte。
Unicode 还有其他的一些重要概念,比如平面 (Plane),我们在之后的文章中会讨论。
4. 结语
本文主要讲了 Unicode 一个非常重要(但是很少被人们提到)的字符编码技术指导模型。
Unicode 作为【统一码】,要解决的问题不仅仅是把所有的人类字符都能编码成功,而且还需要提出一套有效的方案,让编码后的字节长度能满足传输效率。
大家可以想想,假如现在让你完成【人类字符编码成 01】这个历史任务,并且已知我们有 14 万多个字符,你会怎么做?