Unicode (UTF-16 以及 BOM)
2020-12-10
0. 前言
今天这篇聊聊 Unicode 的基本知识、UTF & UCS、UTF-16 以及 BOM 的概念。
1. Unicode 基本知识
1. Unicode 是不是 16-bit 编码?
第一个 Unicode 版本(1991-1995)是 16-bit 编码的,但是 1996 年 7 月开始,第二版 Unicode 就不是这样啦!!
2. Unicode 的编码空间是什么?
标准的 Unicode 编码范围是:U+0000 到 U+10FFFF,这个范围对应的是 21-bit 的编码空间(code space)。
为啥编码范围是 10FFFF 而不是 FFFFFF ?
- 因为我们只有 17 个平面哦~上篇讲过这个概念咯。
21-bit 是怎么算出来的?
- 10FFFF 换算成 bit 就是 1 0000 1111 1111 1111 1111(21 位)
- https://www.rapidtables.com/convert/number/hex-to-binary.html
3. Unicode 是否可以用不同的方式来表示?
根据 Unicode 5 层模型的定义,我们可以选择不同的编码格式来完成 Unicode 编码集和最终编码的映射,比如 UTF-8,UTF-16,UTF-32。
UTF-8, 16, 32 有啥区别?
不同的编码格式最大的区别在于它们的 code unit(编码单位)不同。
-
UTF-8,编码单位 = 8-bit
-
UTF-16,编码单位 = 16-bit
-
UTF-32,编码单位 = 32-bit
-
1 UTF-32 = 2 UTF-16 = 4 UTF-8。
UTF-8 可以用 1-4 个编码单位来做映射,而 UTF-16 只能用 1-2 个编码单位来完成,UTF-32 必须要用 1 个编码单位,所以从空间使用的效率来讲, UTF-8 最好~
Each character will then be represented either as a sequence of one to four 8-bit bytes, one or two 16-bit code units, or a single 32-bit code unit.
不同 UTF 格式之间的区别总结
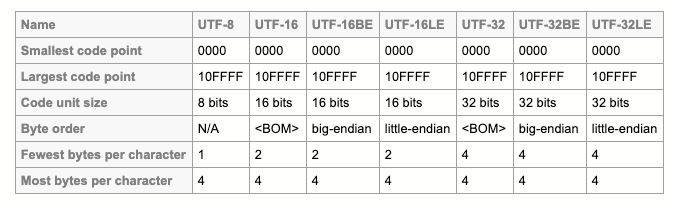
- 最大码位和最小码位都一样(所以才能方便转换);
- 码元(code unit)不同;
- 字节顺序(Byte Order)有点区别(这个概念等下讲);
- 每个字符的最小编码字节数各有不同,最大编码字节数全部是 4 Byte。
2. UTF & UCS
1. UTF 是什么?
Unicode transformation format (UTF) - 通用转换格式。
它是一种算法映射,让每个 Unicode 的码位都可以被映射成为一个独一无二的字节序列(byte sequence)。
注意:这里的码位不包括 Surrogate Code Point - 代理码位(这个概念之后讲)。
A Unicode transformation format (UTF) is an algorithmic mapping from every Unicode code point (except surrogate code points) to a unique byte sequence.
UCS 是什么?
这是一个和 UTF 类似的概念,基本可以互换。
The ISO/IEC 10646 standard uses the term “UCS transformation format” for UTF; the two terms are merely synonyms for the same concept.
2. 可逆性(lossless round tripping)
每个 Unicode 编码后的字符序列都可以再解码还原成原来的字符,所以 UTF 必须要把所有的码位(除了代理码位)都能映射成独一无二的字节序列。这包括了保留码位(reserved/unassigned code points)以及 66 个内部使用字符(noncharacters)。
A “noncharacter” is a code point that is permanently reserved in the Unicode Standard for internal use.
内部使用字符包括 U+FFFE 和 U+FFFF。
Each UTF is reversible, thus every UTF supports lossless round tripping: mapping from any Unicode coded character sequence S to a sequence of bytes and back will produce S again. To ensure round tripping, a UTF mapping must map all code points (except surrogate code points) to unique byte sequences. This includes reserved (unassigned) code points and the 66 noncharacters (including U+FFFE and U+FFFF).
3. UTF-16
前身是一个已经过时的 UCS-2 标准(这个标准无法编码所有的 Unicode 字符);
UCS-2 用 16-bit 编码了 Plane 0 的所有字符,UTF-16 采用了所有的 UCS-2 的 2 Byte 字符编码,然后用 4 Byte 对 UCS-2 无法编码的字符(其他 Plane 的字符)进行了编码。
只要 UCS-2 没有对保留的区间(U+D800-U+DFFF)进行编码,就是有效的 UTF-16 编码。
UTF-16 只用 2 Byte 或 4 Byte 来编码。
UTF-16
-
用一个单独的 16-bit 码元来编码最常用的 63k 个字符。
-
用一对 16-bit 码元(surrogate)来编码剩下 1M 比较少用到的字符。
4. Byte Order 是什么?
刚才看这张图的时候,大家是不是和我一样,被这个 Byte Order 搞糊涂了?
我的发现
- UTF-8 不涉及这个概念;
- UTF-16 和 32 都有两个变体 - BE 和 LE;
- BE 是 big-endian 的缩写
- LE 是 little-endian 的缩写
- BE 和 LE 都属于 Byte Order Mark;
In the table
indicates that the byte order is determined by a byte order mark, if present at the beginning of the data stream, otherwise it is big-endian.
Byte Order Mark
BOM 是在 data stream 开头的一个 Unicode 字符,用来标记字节顺序和编码格式(是否为 Unicode)。
endian 是什么意思?
- 超过 1 Byte 的数据类型可以用两种方式储存在电脑里,MSB(most significant byte) 在最前面,或者 MSB 在最后。
- MSB 在前的就是 big-endian
- MSB 在后面的就是 Little-endian
- 在数据交换的时候,为了告诉接收信息的那方,当前信息的储存方式到底是 MSB 在前还是 MSB 在后,我们需要用一个 BOM 作为标识,这个字符的唯一作用就是告诉接收信息的那一方,在处理信息之前需要知道数据的顺序。
- 由于 UTF-8 是基于字节的,它没有这个问题(只有超过 1 Byte 的才需要),所以 UTF-8 不需要 BOM,它的字符顺序永远是一致的,没有 LE,BE 这种变体。
- 但是 UTF-8 不需要 BOM 不代表它不可以有 BOM,如果你想的话,我们也可以给 UTF-8 加个专门用来告诉别人,我是 UTF-8 的 BOM(这个 BOM 跟 MSB 无关)
- 比如下面这张图里面,我们可以看到,BE 的标识是 FE FF,而 LE 的标识是 FF FE
- UTF-8 的标识方式是 EF。
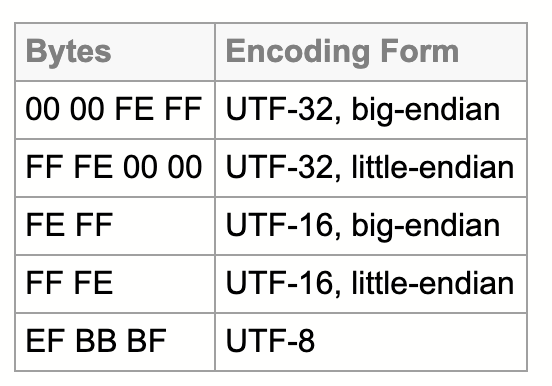
Data types longer than a byte can be stored in computer memory with the most significant byte (MSB) first or last. The former is called big-endian, the latter little-endian. When data is exchanged, bytes that appear in the “correct” order on the sending system may appear to be out of order on the receiving system. In that situation, a BOM would look like 0xFFFE which is a noncharacter , allowing the receiving system to apply byte reversal before processing the data. UTF-8 is byte oriented and therefore does not have that issue. Nevertheless, an initial BOM might be useful to identify the datastream as UTF-8.
UTF-8 加了 BOM 会造成什么问题呢?
有些信息接收方是不需要收到这个 BOM 的,假如你加了,反而会让接收方变糊涂……
UTF-8 can contain a BOM. However, it makes no difference as to the endianness of the byte stream. UTF-8 always has the same byte order. An initial BOM is only used as a signature — an indication that an otherwise unmarked text file is in UTF-8. Note that some recipients of UTF-8 encoded data do not expect a BOM. Where UTF-8 is used transparently in 8-bit environments, the use of a BOM will interfere with any protocol or file format that expects specific ASCII characters at the beginning, such as the use of “#!” of at the beginning of Unix shell scripts.
BOM 符号假如出现在一个字符流的中间(而不是开头)咋办?
假设你在字符流的中间看到了 U+FEFF 这个 BOM,你可以选择:
- 当做 ZWNBSP (ZERO WIDTH NON-BREAKING SPACE) 处理 - 假如要支持老系统
- 当做不支持的字符处理 - 假如你做的是一个新标记语言(markup language)/新数据协议(data protocol)
ZWNBSP
假如你的字符流最前面有个 BOM,那么你的 ZWNBSP 应该怎么表示?
- U+2060 WORD JOINER
假如你的数据没有 BOM,那要怎么表示 LE 和 BE 呢?
用 tag。
- UTF-16BE - big-endian UTF-16
- UTF-16LE - little-endian UTF-16
假如有 BOM,就用 UTF-16 作为 tag。
什么时候应该用不需要 BOM 的协议?
-
当数据有类型的时候(比如数据库里面的一个字段),BOM 就不需要了。
-
当文本数据被标记成带有 LE, BE 的格式(如 UTF-16BE),BOM 是不允许存在的,所有的 U+FEFF 都会被当成 ZWNBSP 来处理。
不当使用 BOM 会浪费空间(毕竟是一个 Byte),还会让字符串的连接(concatenation)变得很复杂(只保留开头的 BOM),甚至会影响数据的相等性比较(假如两个 string,看起来一样,一个带有 BOM,一个不带 BOM,它们就不是 binary-equal 的)
如何处理 BOM?
- 一些协议可能规定必须要 BOM,那你就用;
- 一些协议可能规定 BOM 只需要在没有 tag 的数据里面存在,那么:
- 假如数据流是文本,不确定编码方式,BOM 可以用来做一个编码格式的标记,告诉对方这是 Unicode
- 假如数据流是文本,但是不确定是哪种 endian,那么 BOM 可以用来作为一个 endian 版本的标识,如果没有 BOM,默认是 big-endian。
- 有些基于字节的协议需要在文件开头看到 ASCII 字符,假如我们用的是 UTF-8,就千万别用 BOM(因为它不是一个 ASCII 字符);
- 当你知道数据流的类型时(比如 Unicode BE,Unicode LE),那么就不需要 BOM 了,尤其是当数据流已经有 BE,LE 这样的 tag 时,千万别用 BOM。
5. 还是搞不懂 BOM?
12345
上面这串数字,你是从左到右读,还是从右到左读。
-
从左到右:12345 -> 这是 big-endian
-
从右到左:54321 -> 这是 little-endian
MSB 就是你第一个看到的字符,LSB 就是你最后一个看到的字符。
https://whatis.techtarget.com/definition/most-significant-bit-or-byte
big-endian
12345 这串数字里面,MSB 是 1,LSB 是 5。
little-endian
12345 这串数字里面,MSB 是 5,LSB 是 5。
BOM
告诉你这串数字应该用 big-endian 读,还是用 little-endian 读。
6. 结语
这篇文章主要讲了:
- Unicode 和 UTF-8, UTF-16, UTF-32 的关系(后面三个是不同的实现方式);
- Unicode 的编码空间(21 bit,还记得这个是怎么算的吗?);
- Unicode 对可逆性(lossless round tripping)的要求;
- UTF 和 UCS (UTF-16 的前身是 UCS-2);
- UCS-2 是纯粹的 16-bit 编码,但是后来发现 16-bit 还是不够覆盖所有的字符,于是催生了 Plane(平面)以及 UTF-16 这些新概念;
- UTF-16 和 UTF-32 都是超过 1 Byte 的编码,所以需要 Byte Order 这个概念,本质是由于人们有两种不同的阅读顺序(MSB 在最左边还是最右边);
- MSB 在最左边,就是 Big-endian,也是默认的阅读方式(从左到右);
- BOM 就是为了告诉计算机,字符的顺序是怎么样的(BE 还是 LE),保证字符可以被正确地处理;
PS: ZWNBSP 这个概念我本来没注意的,但是最近工作上正好遇到了一个需要用到 zero-width space 的情况,所以也在文章中提到了。
PPS: BOM 部分主要参考了 Unicode 的官方文档:https://www.unicode.org/faq/utf_bom.html#BOM
是不是又增加了很多奇怪的知识呀(Unicode 系列还没结束哦)。