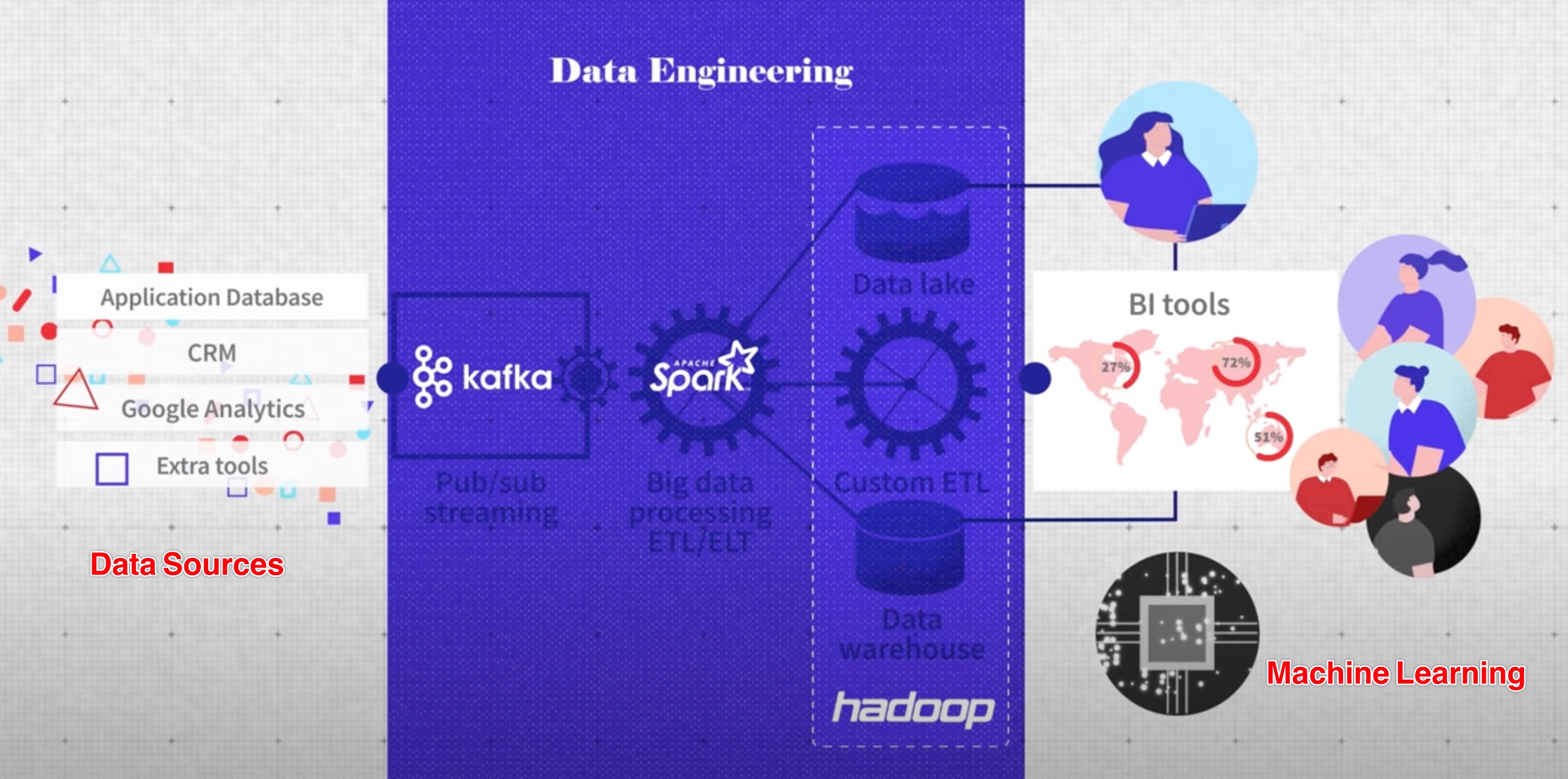
What does a Data Engineer do?
2021-09-25
1. Why do we need Data Engineers?
Goal:
- help other people to do their job (provide business insights)
Input:
- Raw Data from different sources
Output:
- Data for Analytics people to use (DA use BI tools) to visualize data
- Data for Data Scientist to make model and predictions
Process:
- E(xtrac): use API connection to fetch data
- T(ransform): clean data, map data, validate data
- L(oad): load into database
2. Data Storage Optimizations
Data Warehouse
Stores structured data from different sources in a way that suits analytics purpose.
- need to interact with other teams to come up with a good data warehouse design.
- improve the speed (optimized to run complex analytics query)
Data Lake
Stores all the raw data.
ETL will become ELT:
- extract data from different sources
- load raw data into data lake
- transform data (Data Scientists decides how to transform the data)
Data Engineer will do the EL part and Data Scientists do the T part.
3. Data Scientist
- make models to forecast future (e.g. sales for the next quarter)
- access both Data Warehouse and Data Lake
Data Engineer needs to create Custom ETL (ad-hoc task) and provide Data Lake (raw data) for data scientists.
4. Big Data
Characteristics
- Volume
- Variety
- Veracity
- Velocity
Velocity - Data Streaming
Related to the ETL’s Exact part, in big data world, new data is generated in real-time.
In tranditional ETL, we were fetching batch data from source through API requests, this is called Synchronous Communication.
In Big Data world, we need to use Asynchronous Communication by adopting the pub-sub pattern.
- data is divided into different topics
- data subscribers will get data if new data is published
Common technologies:
- Kafka (pub-sub pattern)
Volume - Distributed Storage and Computing
- server cluster will be used to store the data
- scalable is the key
- redundancy is created to ensure data safety
- we need to use a big data processing framework to interact with distributed data
Common technologies:
- hadoop (store data in cluster)
- apache spark (big data ETL/ELT processing framework)
5. Summary
(Big) Data Engineer
Works with ETL/ELT processes to consume data from different data sources and load into Data Warehouse and data lake for business usage.
The design of data warehouse should be suitable for the end users (Data Analysts, Data Scientists, Machine Learning Engineer, etc).
Data Scientists
Consume data from Data Warehouse and Data Lake, develop model and make predictions.
Data Analysts
Consume data from BI interface (linked to Data Warehouse) and develop reports.
Machine Learning Engineer
Make use of the output of ETL and produce some real-time recommendations for the user.