Data Architect Considerations
2021-10-02
0. 前言
今天跟两位 data 从业人士讨论了一些 architect 相关的问题,本文作为记录和总结。
General Principles
在设计架构的时候,大目标是减少对 cloud platform 的依赖度,所以要考虑整个 pipeline 的 decouple,所以我们可以在每层之间都加 abstract layer,尽量做到 flexibility + replaceable。
具体又可以分为 Data Storage 和 Infrastructure 两个大类,从本质上来说,只要我的 data 安全,有相同的 pipeline 来做处理,就可以得到同样的结果,不管换哪个 platform,之后假如要替换一些 component,对整个 workflow 影响都不会太大。
1. Data Storage
为了储存来自不同 data source 的数据,我们需要 data warehouse 和 data lake 来存储数据。
区别在于,data warehouse 里面存的是经过处理的数据,而 data lake 存的是 raw data,虽然都是存储数据,但是目的不同,面对的用户群体也不同。
data lake 是给 Data Scientists 用的,data warehouse 是基于 enterprise user/application 的需求来构建的。
在数据存储方面有个大趋势,就是一站式 data management platform,这个 platform 支持 data lake 和 data warehouse,给不同的 team/application 提供数据,还可以做一些 Data Governance and Security 相关的事情。
一站式的常见选择
databricks 是一个 data management platform,集成了 data lake 和 data warehouse 的优势,所有的 data 都存在这里,是一个 centralized place to access data.
Snowflake 的宣传也是 one platform, many workloads,有 data lake 和 data warehouse 两部分的功能。


Data Warehouse
Firebolt 侧重 decouple,它基于 AWS S3,有 data warehouse 和 data computing 两部分的功能,优势在于数据处理速度很快,用户体验好,可以去 integrate 已有的 S3 data lake 来做 data computing。
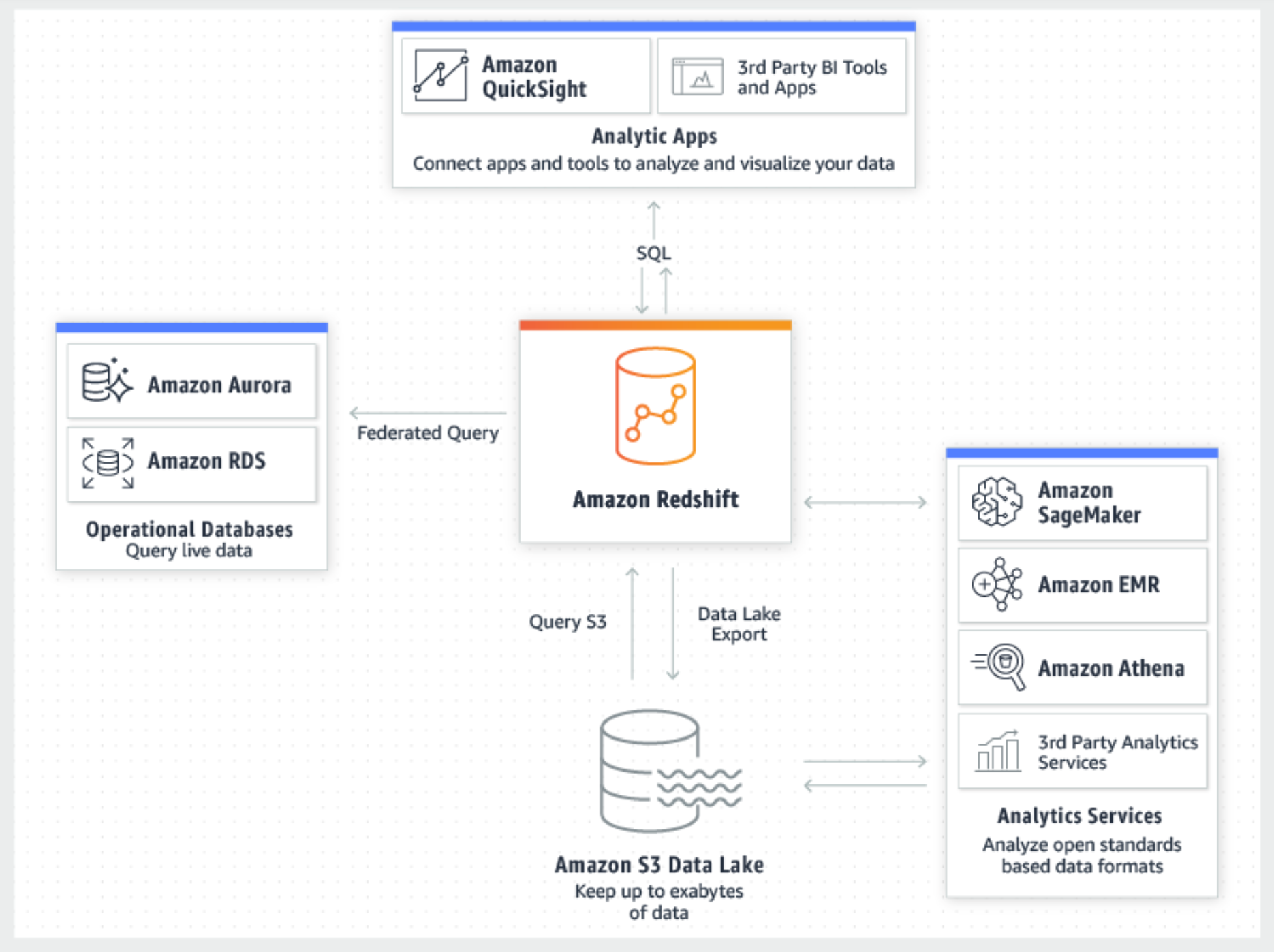
Amazon Redshift 也是一个 data warehouse,可以用 SQL 来 query data lake。
Databricks 也增加了 SQL endpoint 相关的支持。
2. Automation
Hashicorp 是基于三个主流 cloud platform 的一个 abstract layer,它主打的是各种 automation,有四个产品:
- Infrastructure automation: Terraform
- Security automation: Vault
- Networking automation: Consul
- Application automation: Nomad
好处:Automation 可以减少 manual config,通过一些 template 来快速 provision infrastructure,而且 platform independent 这个特性也非常加分,比如我想从 AWS 转到 Azure 可以直接把一套 automation 搬过来。