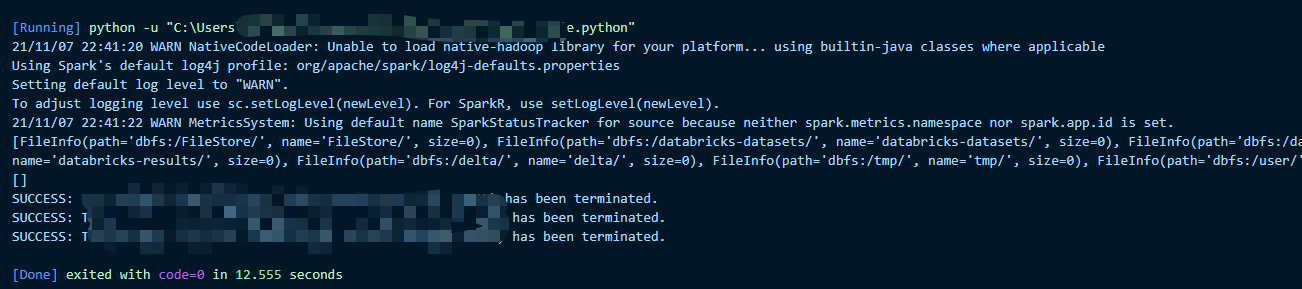
Azure Databricks Environment Setup
2021-11-07
0. Intro
Today I spent some time exploring Azure Databricks service, I find the website UI is not very convenient in terms of writing code (too many mouse operations).
So I decide to set up Databricks with my favourite IDE - VS code, so that I can use my local editor to interact with cluster and run code.
This tutorial aims to help you with the environment setup process (I had a lot of fun with it, so I hope this post can help someone else trying to do the same thing, or my future self who have completely forgotten the steps).
1. Context
Databricks vs Apache Spark
- Databricks is an Analytics Platform based on Apache Spark
- Apache Spark is an Analytics Engine.
Databricks
Databricks is an Apache Spark based Unified Analytics Platform, optimized for the cloud.
Databricks is based on Apache Spark, so it has all the features from Spark, supports multiple languages and libraries, etc.
In short, it is going to do the heavy lifting for us to use Spark.
Azure Databricks
It’s just Databricks running on Azure platform.
- It is an Azure service that allows you to build Apache Spark-based applications.
- It is an analytics platform runs on the cloud, allows you to build Spark applications easily.
Diagram
To help us understand the terminologies, I’ve drawn this diagram to show the relationship of different pieces.
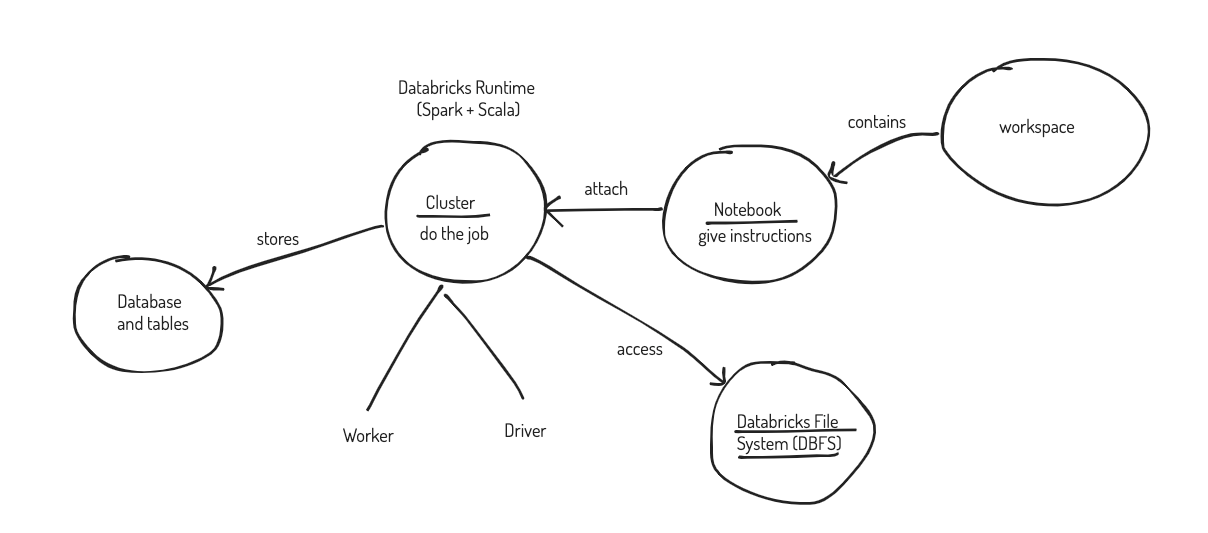
- we need to create a databricks service in Azure portal, it is a workspace with unique url and id
- we can create notebook in databricks workspace, notebook are essentially instructions using different languages to interact with cluster and storage mediums (e.g., DBFS)
- we can create many clusters in the workspace, we can also create a pool to share resources among different clusters
- cluster is the databricks runtime, it has different versions and you can specify how may workers you want to have, you will have to pay for the cluster’s computational resource (DBU is the measurement unit)
- your can attach your notebook to any clusters (or no cluster at all if you don’t need to run anything), once it’s attached, when you run the notebook instructions, for example, load a csv file from DBFS and create a table, the cluster attached will be doing the job based on instructions.
- database and tables are created and stored in the cluster
2. Databricks CLI
Workflow
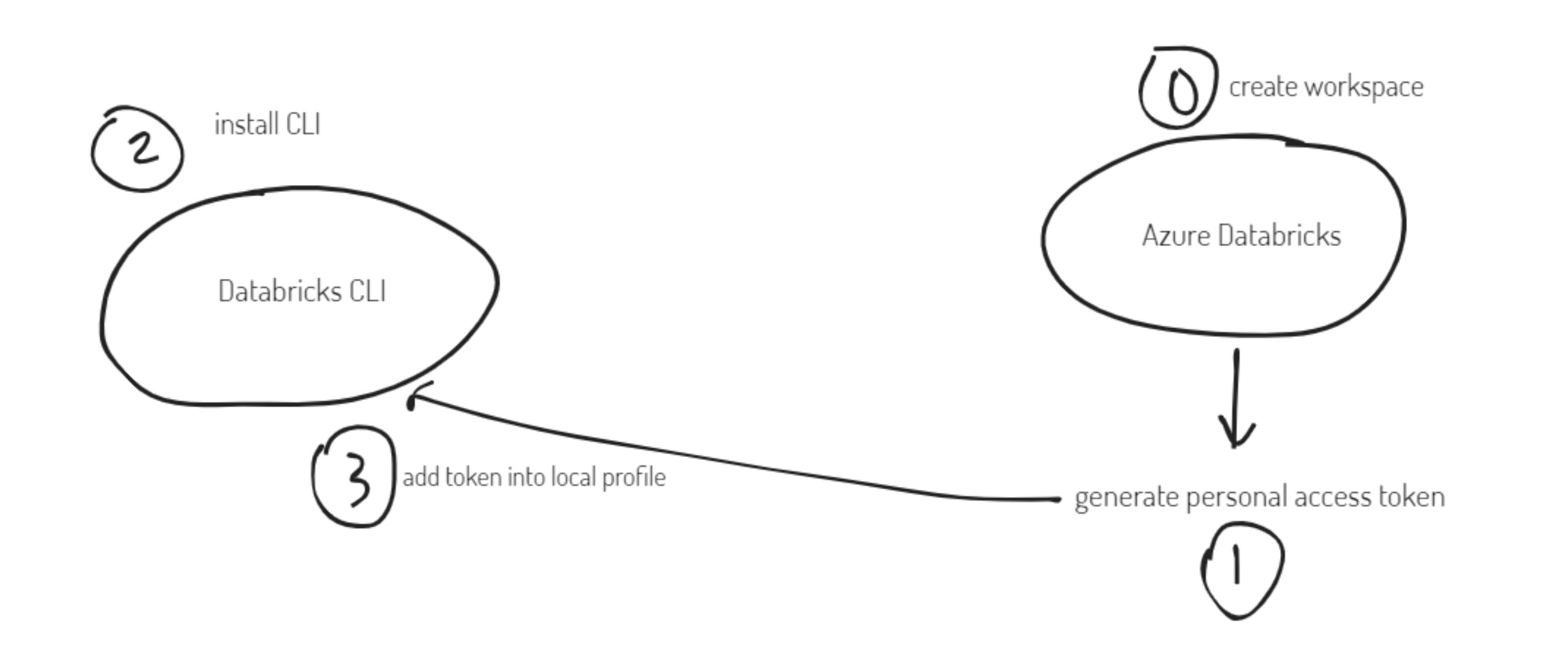
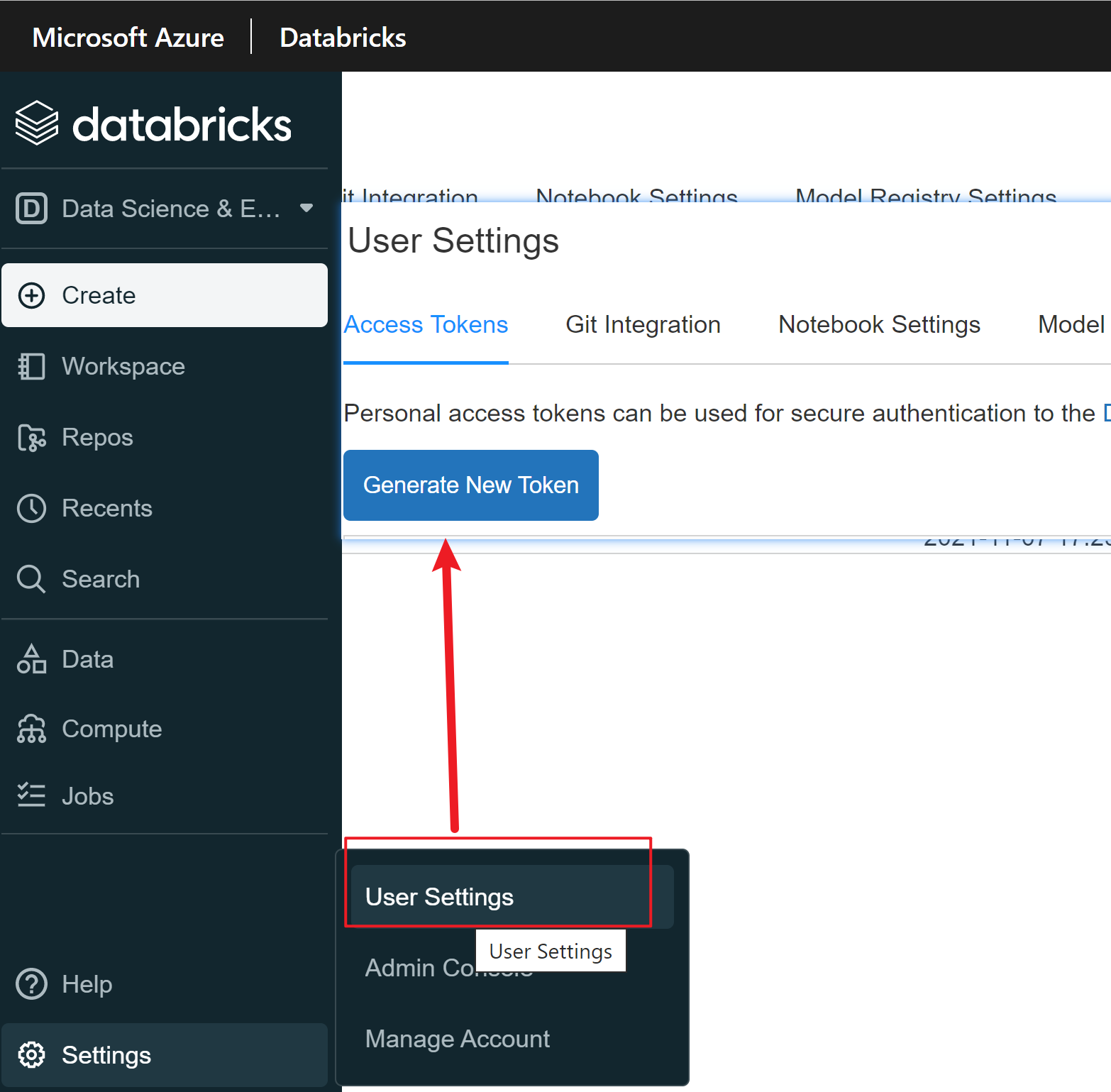
Create workspace and generate token
Note: you also need to create a cluster (go to compute -> cluster -> create), I am using version:
7.3 LTS (includes Apache Spark 3.0.1, Scala 2.12)
Install CLI on local machine
pip install databricks-cli
databricks --version
Note: I’m having issue at this step on MacOS, but it is working fine on my windows machine. Solved: use
pip3 install databricks-cli
Configure profile
# powershell
databricks configure --token
# provide your workspace url, e.g., https://adb-xxxxxxxxx.azuredatabricks.net/
# provide your token
# check the profile
get-content ~/.databrickscfg
Test
databricks fs ls
You should be able to see some folders.
3. Connect with IDE
Reference: https://docs.microsoft.com/en-us/azure/databricks/dev-tools/databricks-connect
1. Install some packages
-
Anaconda: Anaconda | Individual Edition
-
after installation, open the application and launch cmd.exe, create a dbconect in that window
conda create --name dbconnect python=3.7 conda
-
-
Winutil: run the following command in admin mode powershell window, it will download hadoop 2.7 and add into env variables
New-Item -Path "C:\Hadoop\Bin" -ItemType Directory -Force Invoke-WebRequest -Uri https://github.com/steveloughran/winutils/raw/master/hadoop-2.7.1/bin/winutils.exe -OutFile "C:\Hadoop\Bin\winutils.exe" [Environment]::SetEnvironmentVariable("HADOOP_HOME", "C:\Hadoop", "Machine")
2. Install databricks-connect
pip uninstall pyspark
pip install -U "databricks-connect==7.3.*" # or X.Y.* to match your cluster version.
# configure (refer to the official doc to find identifiers)
databricks-connect configure
# test connection
databricks-connect test
3. Download IDE extensions
Databricks Connect - Azure Databricks | Microsoft Docs
For people using VS code, I find the steps pretty straightforward, you need to use Python 3.7 as interpreter, and change some configs in the preference UI, then you can test the connection by running some examples, like the below one (just create a new py file and right click to select run):
from pyspark.sql import SparkSession
from pyspark.dbutils import DBUtils
spark = SparkSession.builder.getOrCreate()
dbutils = DBUtils(spark)
print(dbutils.fs.ls("dbfs:/"))
print(dbutils.secrets.listScopes())
4. Troubleshooting
- conda command not found: please open the anaconda application and launch cmd
- hadoop is not found: please check env variables, point to the directory a level above the Bin folder, e.g., C:\Hadoop is correct, C:\Hadoop\Bin is wrong.
- hadoop is still not found: close your IDE and terminal, restart them.
Success!